Supported Features
Get PDF Information & Form Fields
Extract information from a PDF document, including form fields, page count, size, author, description, keywords, and more.
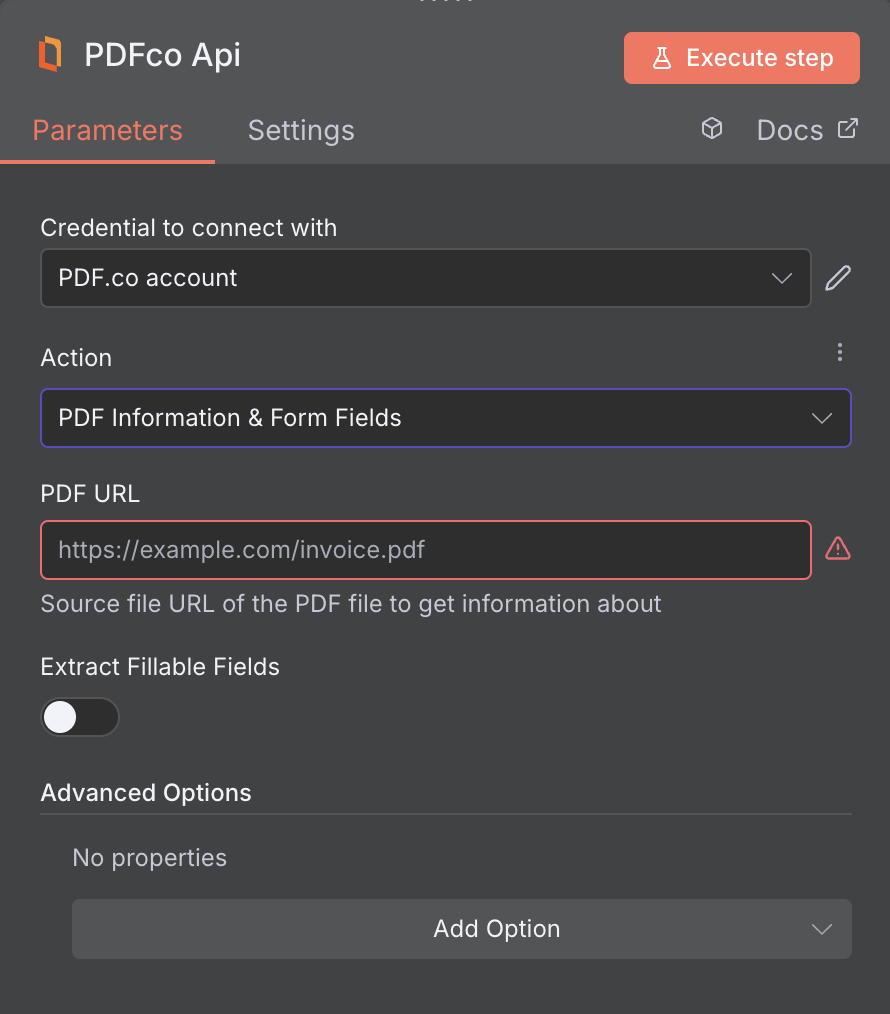
Input
| Name | Description | Required |
|---|---|---|
| PDF URL | Provide the URL to the source PDF document, or a filetoken:// link from PDF.co Built-In Files Storage. If you use another cloud service such as Google Drive or Dropbox ensure the link is publicly accessible. | Yes |
| Extract Fillable Fields | Enable this option to extract information from fillable form fields in the PDF. | No |
| File Name | File name for the generated output, the input must be in string format. | No |
| Webhook URL | The callback URL or Webhook used to receive the output data. | No |
| Output Links Expiration (In Minutes) | Set the expiration time for the output link in minutes. After this specified duration, any generated output file(s) will be automatically deleted from PDF.co Temporary Files Storage. The maximum duration for link expiration varies based on your current subscription plan. To store permanent input files (e.g. re-usable images, pdf templates, documents) consider using PDF.co Built-In Files Storage. | No |
| HTTP Username | HTTP auth user name if required to access source URL. | No |
| HTTP Password | HTTP auth password if required to access source URL. | No |
| Custom Profiles | Use JSON to customize PDF processing with options like output resolution, OCR settings, text extraction methods, encryption, and image handling. Check our Custom Profiles section to see all available parameters for your current endpoint. | No |
Custom Profiles
You can set additional options for the operation used in the PDF.co node by using Custom Profiles. A custom profile is a string in JSON-like format containing predefined parameters. Here’s an example of a Custom Profiles input:| Parameter | Type | Default | Description |
|---|---|---|---|
OCRMode | string | Auto | Specifies how OCR (Optical Character Recognition) should process input content, offering various modes to tailor text extraction based on content type such as images, fonts, and vector graphics. For more information, see OCR Extraction Modes. |
OCRResolution | integer | 300 | Use this parameter to change the OCR resolution from the default 300 dpi. The range is from 72 to 1200 dpi. |
RotationAngle | integer | - | Use manual rotation to handle PDFs with vertically drawn text. Normally, OCR automatically detects page rotation in PDFs and extracts text accurately. However, in some cases, the PDF might not have an actual rotated page --- Rather, the text itself is drawn vertically. In such scenarios, auto-detection may fail. You can use this parameter to manually set the page rotation. The available angles are: 0, 1, 2, 3. |
LineGroupingMode | string | None | Controls line grouping in PDF text extraction. Modes: None (no grouping), GroupByRows (merge rows if all cells align), GroupByColumns (merge cells by column), JoinOrphanedRows (merge single-cell rows to above if no separator). |
ConsiderFontColors | boolean | false | Controls whether font colors should be considered when detecting table structure and merging text objects during PDF extraction. Set to true to consider font colors. |
DetectNewColumnBySpacesRatio | string | 1.2 | Controls how spaces between words are interpreted for column detection in PDF text extraction. It defines the ratio of space width that determines when text should be treated as being in separate columns. |
AutoAlignColumnsToHeader | boolean | true | Controls how columns are detected and aligned during table extraction from PDF documents. It affects both table structure detection and text extraction with formatting preservation. Set to true to automatically align columns to the header row. When set to true (default), the row with the most columns is used as the header, and all other rows are aligned to this structure --- ideal for well-structured tables. When set to false, columns are analyzed independently across all rows to build the structure, which works better for inconsistent or irregular tables. |
OCRImagePreprocessingFilters.AddGammaCorrection() | array[string (float format)] | ["1.4"] | Adds a gamma correction filter to the image preprocessing pipeline used during OCR (Optical Character Recognition). This filter adjusts the brightness and contrast of an image by applying a non-linear gamma correction to improve text recognition quality. |
OCRImagePreprocessingFilters.AddGrayscale() | boolean | false | Set to true to preprocessing filter that converts a colored document/image to grayscale before performing OCR |
DataEncryptionAlgorithm | string | - | Controls the encryption algorithm used for data encryption. See User-Controlled Encryption for more information. The available algorithms are: AES128, AES192, AES256. |
DataEncryptionKey | string | - | Controls the encryption key used for data encryption. See User-Controlled Encryption for more information. |
DataEncryptionIV | string | - | Controls the encryption IV used for data encryption. See User-Controlled Encryption for more information. |
DataDecryptionAlgorithm | string | - | Controls the decryption algorithm used for data decryption. See User-Controlled Encryption for more information. The available algorithms are: AES128, AES192, AES256. |
DataDecryptionKey | string | - | Controls the decryption key used for data decryption. See User-Controlled Encryption for more information. |
DataDecryptionIV | string | - | Controls the decryption IV used for data decryption. See User-Controlled Encryption for more information. |
Output
| Name | Description |
|---|---|
jobId | Unique identifier for the background job. |
pageCount | Number of pages in the PDF document. |
error | Indicates whether an error occurred (false means success) |
status | Status code of the request (200, 404, 500, etc.). For more information, see Response Codes. |
credits | Number of credits consumed by the request |
remainingCredits | Number of credits remaining in the account |
duration | Time taken for the operation in milliseconds |
url | Direct URL to the final PDF file stored in S3. |
name | Name of the output file |
outputLinkValidTill | Timestamp indicating when the output link will expire |