Supported Features
PDF Splitting
Split a single PDF file into multiple PDF files. This operation offers various methods for splitting, including by page number, page range, text search, or barcode search. This feature is particularly useful for segmenting large PDF documents or extracting specific sections.
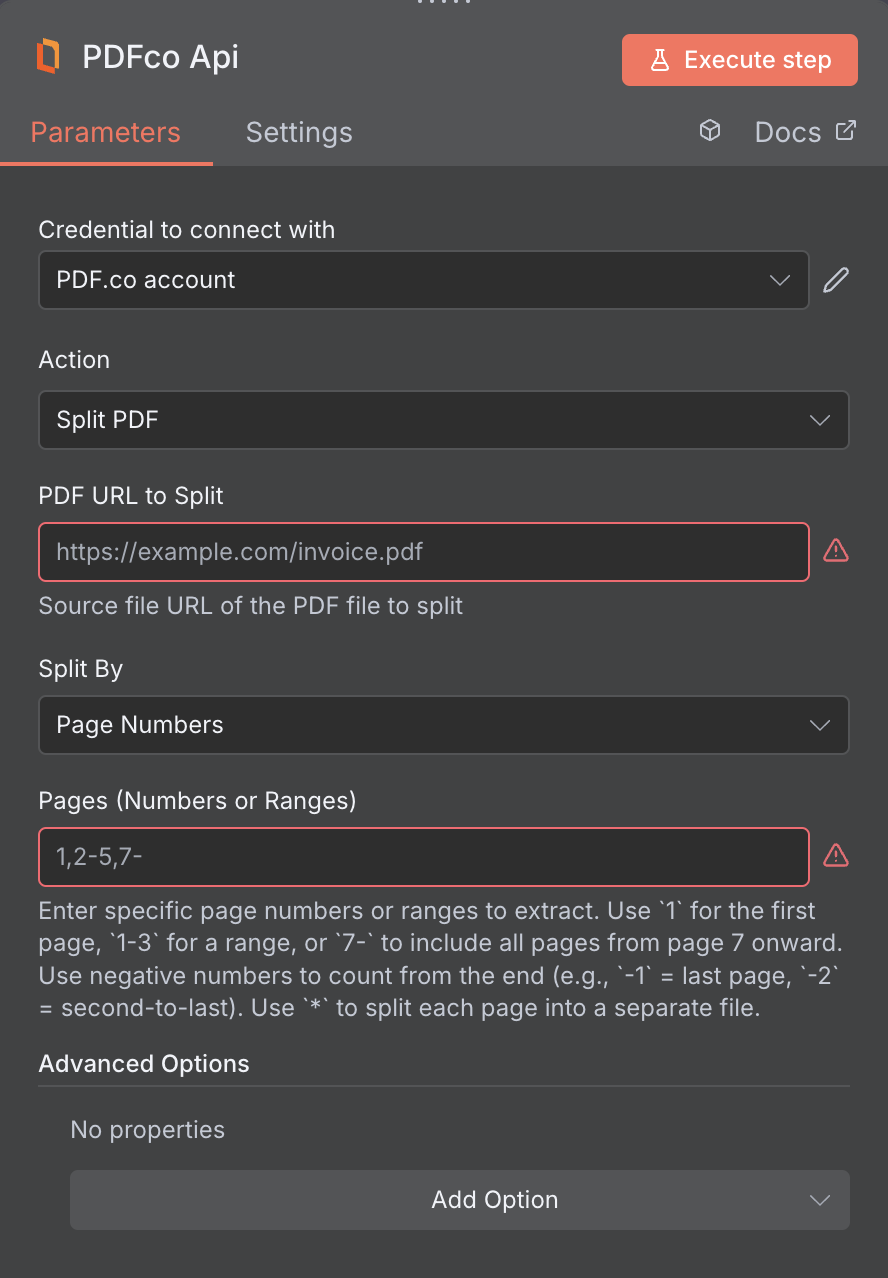
Input
| Name | Description | Required |
|---|---|---|
| PDF URL to Split | Provide the URL to the source PDF document, or a filetoken:// link from PDF.co Built-In Files Storage. If you use another cloud service such as Google Drive or Dropbox ensure the link is publicly accessible. | Yes |
| Split By | Choose how you want to split your PDF file. You can split your PDF based on page numbers, search text, or barcode search. | Yes |
| Page Number or Ranges | Enter specific page numbers or ranges to extract. Use 1 for the first page, 1-3 for a range, or 7- to include all pages from page 7 onward. Use negative numbers to count from the end (e.g., -1 = last page, -2 = second-to-last). Use * to split each page into a separate file. | No, unless you’re using Split by Pages |
| Text Search String | Enter the text to search for in PDF. Must be a String. | No, unless you’re using Split by Search Text |
| Barcode Search String | Enter the barcode macros string in PDF. See this guidance below to Split your PDF based on barcode search. | No, unless you’re using Split by Barcode |
| Case-Sensitive Search | Enable case-sensitive search. | No |
| Regular Expression Search | Enable regular expression search for the Search String parameter. | No |
| Exclude Pages with Identified Text | Exclude pages where the Search String text was found. | No |
| OCR Language | Set the language for OCR (text from image) to use for scanned PDF, PNG, and JPG documents input when extracting text. | No |
| File Name | File name for the generated output, the input must be in string format. | No |
| Webhook URL | The callback URL or Webhook used to receive the output data. | No |
| HTTP Username | HTTP auth user name if required to access source URL. | No |
| HTTP Password | HTTP auth password if required to access source URL. | No |
| Custom Profiles | Use JSON to customize PDF processing with options like output resolution, OCR settings, text extraction methods, encryption, and image handling. Check our Custom Profiles section to see all available parameters for your current endpoint. | No |
Custom Profiles
You can set additional options for the operation used in the PDF.co node by using Custom Profiles. A custom profile is a string in JSON-like format containing predefined parameters. Here’s an example of a Custom Profiles input:base64 format. You can find the list of available parameters for customizing profiles in the PDF.co operation documentation below:
| Parameter | Type | Default | Description |
|---|---|---|---|
outputDataFormat | string | - | If you require your output as base64 format, set this to base64 |
DataEncryptionAlgorithm | string | - | Controls the encryption algorithm used for data encryption. See User-Controlled Encryption for more information. The available algorithms are: AES128, AES192, AES256. |
DataEncryptionKey | string | - | Controls the encryption key used for data encryption. See User-Controlled Encryption for more information. |
DataEncryptionIV | string | - | Controls the encryption IV used for data encryption. See User-Controlled Encryption for more information. |
DataDecryptionAlgorithm | string | - | Controls the decryption algorithm used for data decryption. See User-Controlled Encryption for more information. The available algorithms are: AES128, AES192, AES256. |
DataDecryptionKey | string | - | Controls the decryption key used for data decryption. See User-Controlled Encryption for more information. |
DataDecryptionIV | string | - | Controls the decryption IV used for data decryption. See User-Controlled Encryption for more information. |
Output
| Name | Description |
|---|---|
jobId | Unique identifier for the background job. |
pageCount | Number of pages in the PDF document. |
error | Indicates whether an error occurred (false means success) |
status | Status code of the request (200, 404, 500, etc.). For more information, see Response Codes. |
credits | Number of credits consumed by the request |
remainingCredits | Number of credits remaining in the account |
duration | Time taken for the operation in milliseconds |
url | Direct URL to the final PDF file stored in S3. |
name | Name of the output file |
outputLinkValidTill | Timestamp indicating when the output link will expire |